| 7. FEJEZET | Tartalom | A. FÜGGELÉK |
8. FEJEZET:
Kapcsolódás a UNIX operációs rendszerhez
A UNIX operációs rendszer szolgáltatásai a C nyelvű programokból az ún. rendszerhívásokon keresztül érhetők el. Ezek a rendszerhívások lényegében adott feladatot ellátó függvények, amelyeket a felhasználói program hívhat. Ebben a fejezetben a C nyelvű programokból hívható legfontosabb rendszerhívásokat ismertetjük. Ha a UNIX operációs rendszer alatt dolgozunk, akkor ezek a függvények közvetlenül a segítségünkre lehetnek. A rendszerhívásokat gyakran alkalmazzuk a program maximális hatékonyságának elérése érdekében vagy a könyvtári függvényekkel nem megvalósítható feladatok ellátására. Abban az esetben, ha a C nyelvet nem UNIX operációs rendszerrel használjuk, akkor az itt közölt példákon keresztül betekinthetünk a C nyelvű programozás rejtelmeibe, és bár a részletek változhatnak, más operációs rendszer esetén is hasonló programok írhatók. Mivel az ANSI C könyvtár sok esetben a UNIX szolgáltatásait modellezi, az itt közölt programok a könyvtár jobb megismerését is segítik.
A fejezet anyaga három fő részre oszlik, az adatbevitel és adatkivitel, az állománykezelés és a tárkezelés műveleteire. Az első két rész feltételezi a UNIX jellemzőinek legalább alapfokú ismeretét.
A 7. fejezet az adatbevitel és adatkivitel olyan rendszerillesztési felületével foglalkozott, ami lényegében operációs rendszertől függetlenül egységes, mivel bármelyik konkrét rendszerben a standard könyvtár eljárásait a befogadó rendszer szolgáltatásainak figyelembevételével kell megírni. A következő néhány pontban a UNIX rendszer adatbevitellel és adatkivitellel kapcsolatos rendszerhívásait ismertetjük, és megmutatjuk, hogy ezekhez hogyan készíthetjük el a standard könyvtár megfelelő részeit.
8.1. Az állományleírók
A UNIX operációs rendszerben az összes adatbeviteli és adatkivíteli művelet állományok olvasásával vagy írásával valósul meg, mivel az összes perifériához való hozzáférés, beleértve a billentyűzetet és a képernyőt is, az állománykezelő rendszeren keresztül történik. Ez azt jelenti, hogy a felhasználói program és a perifériák közötti teljes adatcsere egyetlen homogén interfészen át bonyolódik le.
A legáltalánosabb esetben egy állomány olvasása vagy írása előtt szándékunkról tájékoztatni kell az operációs rendszert, és ezt a folyamatot az állomány megnyitásának nevezzük. Ha egy állományba írni akarunk, akkor szükség lehet az adott állomány létrehozására vagy a már meglévő állomány korábbi tartalmának törlésére. Az operációs rendszer ellenőrzi, hogy mindehhez van-e jogunk (A megadott állomány létezik-e? Van-e hozzáférési jogunk az állományhoz?), és ha mindent rendben talált, akkor visszatér a hívó programba egy kis, nem negatív egész számmal, amit állományleírónak nevezünk. Ezután minden esetben, amikor az állományból olvasni vagy abba írni akarunk, az állomány azonosítására az állománynév helyett ezt az állományleírót használjuk. (Az állományleíró a standard könyvtárban használt állománymutatóval vagy az MS-DOS-ban használt állománykezelővel analóg fogalom.) A megnyitott állományra vonatkozó össze információt az operációs rendszer kezeli és a felhasználói program az állományra csak annak állományleírójával hivatkozik.
Mivel leggyakrabban a billentyűzeten és a képernyőn keresztüli adatbevitelt és adatkivitelt használjuk, ezért ezek kezelésére egy kényelmes megoldását fejlesztettek ki. Amikor az operációs rendszer parancsértelmezője (a shell) egy felhasználói programot futtat, ahhoz automatikusan három állományt nyit meg. Ezek (ahogyan erről már volt szó) a standard bemenet, a standard kimenet és a standard hibaállomány, amelyekhez rendre a 0,1 és 2 állományleíró tartozik. Így ha egy program mindig a 0 leírójú állományt olvassa és az 1, ill. 2 leírójú állományba ír, akkor nem kell törődnie az állományok megnyitásával.
A felhasználó a < vagy > jelekkel átirányíthatja a program bemenetét vagy kimenetét a
prog <beallomany >kiallomanyformában. Ilyenkor a shell megváltoztatja a 0 és 1 állományleíróhoz tartozó alapértelmezés szerinti hozzárendelést az adott nevű állományokra. Normális esetben a 2 állományleíróhoz mindig a képernyő van hozzárendelve, így a hibaüzenetek mindig ott jelennek meg. Hasonló módon történik a bemenet és a kimenet kezelése pipeing mechanizmus alkalmazásakor. Minden esetben az állományok hozzárendelését az operációs rendszer (shell) változtatja meg és nem a felhasználói program. A programnak nincs tudomása arról, hogy honnan kapja a bemeneti adatokat és hová kerülnek a kimeneti adatok, mindössze csak azt tudja, hogy a 0 állomány bemenet, az 1 és 2 állomány kimenet.
8.2. Alacsony szintű adatbevitel és adatkivitel – a read és write függvények
A UNIX rendszerben az alacsony szintű adatbevitelt és adatkivitelt a read és write rendszerhívások intézik, amelyek a C nyelvű programból a read és write függvényekkel érhetők el. Mindkét függvény első argumentuma az állományleíró, a második argumentum pedig a felhasználói programban definiált karakteres tömb (puffer), amibe a bejövő adatok érkeznek, ill. aminek a tartalma kiíródik. A függvények harmadik argumentuma az átvinni kívánt bájtok (karakterek) száma. A függvények használatának módja:int n_olvas = read(int fd, char *buf, int n); int n_ir = write(int fd, char *buf, int n);Mindegyik függvény a ténylegesen átvitt bájtok számával tér vissza, ami olvasáskor kisebb lehet, mint a híváskor megadott érték. A visszatérési érték 0, ha állomány vége következett és -1, ha valamilyen hiba történt. Íráskor a visszatérési értéknek meg kell egyezni a kiíratni kívánt bájtszámmal, ha nem egyeznek, akkor hiba történt az átvitel közben.
Egy függvényhívással bármennyi bájt írható vagy olvasható. A leggyakoribb esetben a bájtszám 1, ami azt jelenti, hogy egy időben egyetlen karaktert írunk vagy olvasunk (puffereletlen adatátvitel). Gyakori még az 1024, 4096 vagy hasonló számú bájt átvitele, mivel ez a blokkméret jól illeszkedik a perifériák fizikai blokkméretéhez. Nagyobb méretű blokkok átvitele hatékonyabb, mivel fajlagosan kevesebb rendszerhívásra van szükség.
Az elmondottak alapján írjunk egy egyszerű programot, amely a bemenetről érkező adatokat átmásolja a kimenetre. (A program lényegében megegyezik az 1. fejezetben leírt másolóprogrammal.) Ez a program gyakorlatilag bármit bárhová átmásol, mivel a bemenet és a kimenet tetszőleges eszközre vagy állományba átirányítható.
#include "syscalls.h" main()/* a bemenetet a kimenetre másolja */ { char buf[BUFSIZ]; int n; while (n = read(0, buf, BUFSIZ)) > 0) write (1, buf, n); return 0; }A rendszerhívások függvényprototípusait a syscalls.h headerben gyűjtöttük össze, ahonnan a fejezet programjaiba beiktathatók. Ez a header-név természetesen nem szabványban rögzített név.
A BUFSIZ paramétert szintén a syscalls.h headerben definiáltuk, értéke a helyi rendszerhez illeszkedően lett megválasztva. Ha az állomány mérete nem a BUFSIZ egész számú többszöröse, akkor a read a write függvénnyel kiírt bájtszámnál kisebb számmal fog visszatérni és a következő read visszatérési értéke nulla lesz (EOF).
Érdemes megnézni, hogy hogyan használható a read és a write magasabb szintű (getchar vagy putchar függvényekhez hasonló) függvények előállítására. Példa gyanánt írjuk meg a getchar puffereletlen bemeneti függvényt, amely egy időben egy karaktert olvas a standard bemenetről.
#include "syscalls.h" /* getchar: egykarakteres, puffereletlen beolvasóeljárás */ int getchar(void) { char c; return (read(0, &c, 1) == 1) ? (unsigned char) c : EOF; }A programban c karakteres kell hogy legyen, mivel a read függvény karakteres mutatót igényel. A visszatéréskor c-re rákényszerített unsigned char típus garantáltan kizárja az előjel-kiterjesztésből adódó problémákat.
A getchar második változata egyszerre egy nagy adatblokkot olvas be és abból egyenként adja ki a karaktereket.
#include "syscalls.h" /* getchar: egyszerű puffereit változat */ int getchar(void) { static char buf[BUFSIZ]; static char *bufp = buf; static int n = 0; if (n == 0) { /* a puffer üres */ n = read(0, buf, sizeof buf); bufp = buf; } return (--n >= 0) ? (unsigned char) *bufp++ : EOF; }Ha a getchar ezen változatát az <stdio.h> header beiktatásával lefordítjuk, akkor a getchar nevet a #undef paranccsal definiálatlanná kell tenni, különben a rendszer a könyvtári makrót szerkesztené be a programba.
8.3. Az open, creat, close és unlink rendszerhívások
Az alapértelmezés szerinti standard bemenet, kimenet és hibaállomány kivételével az összes többi, írásra vagy olvasásra igénybe vett állományt explicit módon meg kell nyitni. Erre a célra két rendszerhívás, az open és a creat (vigyázat: nem create) használható.
Az open hasonló a 7. fejezetben leírt fopen függvényhez, kivéve, hogy állománymutató helyett egy állományleíróval tér vissza, ami int típusú.
Az open visszatérési értéke -1, ha a művelet közben valamilyen hiba történt. Az open használatát mutatja be a következő programrészlet.
#include <fcntl.h> int fd; int open(char *nev, int jelzo, int eng); fd = open(nev, jelzo, eng);Csakúgy, mint a fopen esetén, a nev argumentum az állomány nevét tartalmazó karaktersorozat. A második, jelzo argumentum int típusú és azt mondja meg, hogy az állományt milyen célból nyitottuk meg. Gyakrabban előforduló értékei:
0_RDONLY megnyitás csak olvasásra; 0_WRONLY megnyitás csak írásra; 0_RDWR megnyitás írásra és olvasásra.Ezek az állandók System V UNIX rendszer esetén az <fcntl.h> headerben, a Berkeley (BSD) változat esetén pedig a <sys/file.h> headerben vannak definiálva. Egy létező állomány megnyitása olvasásra:
fd = open(nev, 0_RDONLY, 0);Az open harmadik, eng argumentuma ilyen típusú alkalmazások esetén mindig nulla. (Az eng paraméter használatára még visszatérünk.)
Ha egy nem létező állományt akarunk megnyitni, akkor hibajelzést kapunk. Egy új állomány létrehozása vagy egy meglévő állomány felülírása a creat rendszerhívással lehetséges. Ennek általános alakja:
int creat(char *nev, int eng); fd = creat(nev, eng);A creat függvény a hívása után az állományleíróval tér vissza, ha képes volt létrehozni a kívánt állományt, vagy a -1 értékkel, ha nem. Ha a creat-nek megadott állomány már létezett, akkor a függvény a hosszúságát nullára állítja, amivel a korábbi tartalmat törli. Nem hiba a creat függvénynek már létező állomány nevét megadni.
Ha az állomány még nem létezik, akkor a creat az eng argumentumban megadott védelmi móddal hozza azt létre. A UNIX rendszerben minden állományhoz egy kilenc-bites védelmi kód tartozik, ami az állomány írási, olvasási, végrehajtás-hozzáférési, tulajdonosi és tulajdonoscsoporthoz tartozó engedélyeket tartalmazza. A védelmi kódot legkényelmesebben egy háromjegyű oktális számmal adhatjuk meg. Így pl. a 0755 kód a tulajdonosnak engedélyezi az írást, olvasást és a végrehajtást, a csoport többi tagjának és mindenki másnak is viszont csak olvasást és végrehajtást enged meg.
Az elmondottak illusztrálására ismertetjük a UNIX cp programjának egyszerűsített változatát, amely egy állományt egy másik állományba másol. Az itt közölt változat csak egy állományt másol, és nem engedi meg, hogy a második argumentum egy könyvtár legyen. Ugyancsak egyszerűsíti a feladatot, hogy a program rögzített védelmi kódot használ.
#include <stdio.h> #include <fcntl.h> #include "syscalls.h" #define ENG 0666 /* olvasás-írás a tulajdonosnak, a csoportnak és másoknak */ void error (char *, ...); /* cp: f1 másolása f2-be */ main (int argc, char *argv[]) { int f1, f2, n; char buf[BUFSIZ]; if (argc != 3) error ("Felhasználás: cp a-ból b-be"); if ((f1 = open (argv[1], 0_RDONLY, 0)) == -1) error ("cp: nem nyitható meg %s", argv[1]); if ((f2 = creat (argv[2], ENG)) == -1) error ("cp: nem hozható létre %s, mód %03o", argv[2], ENG); while ((n = read (f1, buf, BUFSIZ)) > 0) if (write (f2, buf, n) != n) error ("cp: írási hiba a %s állományban", argv[2]); return 0; }A program 0666 védelmi kóddal egy kimeneti állományt hoz létre. A rögzített védelmi kód helyett felhasználhatjuk a bemeneti állomány eredeti védelmi kódját is, amit a 8.6. pontban ismertetendő stat rendszerhívással kérdezhetünk le.
Vegyük észre, hogy az error függvényt változó hosszúságú argumentumlistával hívjuk, hasonlóan a korábban ismertetett printf függvényhez. Az error függvény programja egyben példát mutat a printf függvénycsalád egy újabb tagjának használatára. A standard könyvtár vprintf függvénye a printf függvényhez hasonló, annyi eltéréssel, hogy a változó hosszúságú argumentumlistát egyetlen, a va_start makró hívásával inicializált argumentum helyettesíti. A hasonlóan kialakított vfprintf és vsprintf függvények az fprintf és sprintf függvényeknek felelnek meg.
#include <stdio.h> #include <stdlib.h> #include <stdarg.h> /* error: kiír egy hibaüzenetet és leállítja a program futását */ void error (char *fmt, ...) { va_list args; va_start (args, fmt); fprintf (stderr, "Hiba: "); vfprintf (stderr, fmt, args); fprintf (stderr, "\n"); va_end (args); exit (1); }A program által egy időben megnyitható állományok száma korlátozott, de ez a korlát gyakran 20 körül van. Ezért minden programot, amely több állományt használ, úgy kell kialakítani, hogy az állományleírók újra felhasználhatók legyenek. Az állományleíró és a megnyitott állomány közötti kapcsolat a close (int fd) függvénnyel szakítható meg, az így felszabaduló állományleíró más állományokhoz használható. A close függvény lényegében megfelel a standard könyvtár fclose függvényének, kivéve, hogy a puffert nem üríti ki. A programot a main függvényében kiadott exit vagy return utasítással leállítva az összes megnyitott állomány automatikusan lezáródik.
Az unlink(char *nev) függvény eltávolítja a nev nevű állományt az állománykezelő rendszerből. Az unlink a standard könyvtár remove függvényének felel meg.
8.1. gyakorlat. Írjuk újra a 7. fejezetben megismert cat programot úgy, hogy a standard könyvtári függvények helyett a read, write, open és close függvényeket használjuk! Végezzünk kísérleteket a két változat futási idejének meghatározására!
8.4. A véletlenszerű hozzáférés – az lseek függvény
Normális körülmények között a bemenet és a kimenet szekvenciális: minden egyes read vagy write hívással az állomány következő karakterpozíciójához férünk hozzá. Szükség esetén azonban az állomány tetszőleges sorrendben írható vagy olvasható. Ezt az lseek rendszerhívás teszi lehetővé, amellyel tényleges olvasás vagy írás nélkül tetszőlegesen mozoghatunk az állományban. Az lseek általános alakja:long lseek(int fd, long offset, int bazis);A függvény hívásakor az fd állományleíróval kijelölt állomány aktuális hozzáférési pozícióját az offset-nek megfelelő helyre állítja. Ez a hely egy relatív pozíció a bázis kezdőponthoz képest. Az állomány soron következő írása vagy olvasása az lseek függvénnyel beállított helyen fog kezdődni. A bázis kezdőpont értéke 0, 1 vagy 2 lehet attól függően, hogy az offset-et az állomány elejétől, az aktuális pozíciótól vagy az állomány végétől számoljuk. Például ha egy állományhoz további adatokat akarunk hozzáfűzni (ez a UNIX shell >> átirányítási parancsával vagy az fopen "a" hozzáférési módjával valósítható meg), akkor az írás előtt meg kell keresni az állomány végét, amit az
lseek (fd, 0L, 2);utasítással érhetünk el. Hasonló módon az állomány elejére pozicionálás („visszatekercselés”, rewind) az
lseek (fd, 0L, 0);utasítás hatására jön létre.
A 0L értékű argumentumot (long) 0 formában is írhatnánk, vagy megfelelően deklarált lseek esetén akár 0 formában.
Az lseek függvény felhasználásával az állományok a nagyméretű tömbökhöz hasonlóan kezelhetők, de az adatokhoz való hozzáférés nagyon lelassul. A következő példaprogram egy állomány tetszőleges helyéről tetszőleges számú bájtot olvas, és visszatér a beolvasott bájtok számával, vagy ha olvasás közben hiba történt, akkor -1 értékkel.
#include "syscalls.h" /* get: n db bájtot olvas a pos pozíciótól kezdve */ int get (int fd, long pos, char -buf, int n) { if (lseek (fd, pos, 0) >= 0) /* beáll a pos helyre */ return read (fd, buf, n); else return -1; }Az lseek visszatérési értéke long típusú és megadja az állományon belüli új pozíciót, vagy ha hiba fordult elő, akkor -1 értékű. A standard könyvtár fseek függvénye hasonló az lseek függvényhez, annyi különbséggel, hogy az fseek első argumentuma FILE * típusú és a visszatérési értéke nem nulla, ha hiba jelentkezett.
8.5. Példa: az fopen és getc függvények megvalósítása
A következőkben az eddigieket megpróbáljuk egységbe foglalni az fopen és getc könyvtári függvények megvalósításával.
Emlékezzünk arra, hogy a standard könyvtári függvények az állományokat az állománymutatóval írják le és nem pedig az állományleíróval. Az állománymutató egy struktúrát címez, amelyben az állományra vonatkozó különböző információk (egy puffert címző mutató, amit felhasználva az állomány nagyobb blokkokban kezelhető; a pufferban maradt karakterek száma; a puffer következő karakterét címző mutató; az állományleíró; az írási-olvasási módot megadó jelzők; hibaállapotjelzők stb.) találhatók.
Az állományokat leíró adatstruktúra a <stdio.h> headerben van, amit minden olyan forrásállományba be kell építeni (#include utasítással), amely a standard bemeneti-kimeneti könyvtár eljárásait használja. Természetesen a könyvtár függvényeit is be kell építeni a forrásprogramba. A következőkben ismertetjük az <stdio.h> egy részletét. Azok a nevek, amelyeket csak a könyvtár függvényei használhatnak, aláhúzással kezdődnek, ami csökkenti annak esélyét, hogy véletlenül megegyezzen egy, a programban használt névvel. Ezt a jelölésmódot használja az összes standard könyvtári eljárás.
#define NULL 0 #define EOF (-1) #define BUFSIZ 1024 #define OPEN_MAX 20 /* egy időben nyitott állományok száma */ typedef struct_iobuf { int cnt; /* a pufferban maradt karakterek száma */ char *ptr; /* a következő karakterpozíció */ char *base; /* a puffer kezdőcíme */ int flag; /* az állomány-hozzáférés módja */ int fd; /* az állományleíró */ } FILE; extern FILE iob[OPEN_MAX]; #define stdin (&_iob[0]) #define stdout (&_iob[1]) #define stderr (&_iob[2]) enum _flags { _READ = 01, /* állomány megnyitása olvasásra */ _WRITE = 02, /* állomány megnyitása írásra */ _UNBUF = 04, /* az állomány puffereletlen */ _EOF = 010, /* az állományban EOF található */ _ERR = 020 /* az állományban hiba volt */ }; int _fillbuf(FILE *); int flushbuf(int, FILE *); #define feop(p) (((p)->flag & _EOF) != 0) #define ferror(p) (((p)->flag & _ERR) != 0) #define fileno(p) ((p)->fd) #define getc(p) (--(p)->cnt >= 0 ? \ (unsigned char) *(p)->ptr++ : _fillbuf(p)) #define putc(x, p) (--(p)->cnt >= 0 ? \ *(p)->ptr++ \ = (x) : _flushbuf( (x), p)) #define getchar() getc(stdin) #define putchar(x) putc((x), stdout)A getc makró normális esetben dekrementálja a darabszámot, lépteti a mutatót és visszatér a karakterrel. (Emlékeztetőül: a \ azt jelzi a fordítóprogramnak, hogy a definíció a következő sorban folytatódik!) Ha a pufferban maradt karakterek száma (vagyis adarabszám) negatív lesz, a getc hívja a _fillbuf függvényt, ami újra feltölti a puffert, inicializálja a struktúra tartalmát és visszatér egy karakterrel. A visszatéréskor adott karakter unsigned típusú, ami garantálja, hogy az összes karakter pozitív lesz.
Bár részleteiben nem tárgyaljuk, mégis beiktattuk a putc függvény definícióját is, annak bemutatására, hogy lényegében ugyanúgy működik, mint a getc függvény, vagyis ha a puffer megtelt, hívja a _flushbuf függvényt. A közölt részlet a hibaállapotot, az állomány végét és az állományleírót kezelő makrókat is tartalmazza.
Ennyi bevezető információ birtokában már megírhatjuk az fopen függvényt! Az fopen legnagyobb része azzal foglalkozik, hogy megnyitja az állományt, a kívánt helyre pozícionál és a helyes állapotnak megfelelően állítja be a jelzőbiteket. Az fopen nem foglalja le a pufferterületet, ezt az első olvasáskor a _fillbuff teszi meg.
#include <fcntl.h> #include "syscalls.h" #define ENG 0666 /* írás, olvasás a tulajdonosnak, a csoportnak és másoknak */ /* fopen: megnyit egy állományt, visszatér az állománymutatóval */ FILE *fopen(char *nev, char *mod) { int fd; FILE *fp; if (*mod != 'r' && *mod != 'w' && *mod != 'a') return NULL; for (fp = _iob; fp < _iob + OPEN_MAX; fp++) if ((fp->flag & (_READ | _WRITE)) == 0) break; /* szabad területet talált */ if (fp >= _iob + OPEN_MAX) /* nincs szabad hely */ return NULL; if (*mod == 'w' ) fd = creat(nev, ENG); else if (*mod == 'a') { if((fd = open(nev, 0_WRONLY, 0)) == -1) fd = creat(nev, ENG); lseek(fd, 0L, 2); } else fd = open(nev, 0_RDONLY, 0); if (fd == -1) /* a név nem érhető el */ return NULL; fp->fd = fd; fp->cnt = 0; fp->base = NULL; fp->flag = (*mod == 'r') ? _READ : _WRITE; return fp; }Az fopen itt ismertetett változata nem kezeli a szabványban megengedett összes hozzáférési módot, de ezek utólag viszonylag könnyen beépíthetők a programba. A program a "b" bináris hozzáférést sem kezeli, de ennek UNIX operációs rendszer esetén nincs is jelentősége. Ezenkívül nem veszi figyelembe az írásra és olvasásra egyaránt igénybe vehető állományt jelző "+" hozzáférési módot sem.
A getc adott állományra vonatkozó első hívásakor a darabszám nulla, ami a _fillbuf függvény hívását eredményezi. Ha a _fillbuf úgy találja, hogy az állomány nincs megnyitva olvasásra, akkor azonnal EOF jelzéssel tér vissza. Megnyitott állomány esetén pedig megpróbál a puffer számára tárterületet lefoglalni (ha az olvasás pufferelt). Ha a puffer létrejött (lefoglalta a területet számára), akkor a _fillbuf hívja a read függvényt, amely azt adatokkal tölti fel, beállítja a darabszámot és a mutatókat, majd a puffer elején lévő karakterrel tér vissza. A _fillbuf a további hívásoknál már a meglévő puffert használja.
#include "syscalls.h" /* _fillbuf: területet foglal a puffernek és feltölti */ int fillbuf(FILE *fp) { int bufsize; if ((fp->flag&(_READ|_EOF|_ERR)) !=_READ) return EOF; bufsize = (fp->flag & _UNBUF) ? 1 : BUFSIZ; if (fp->base == NULL) /* még nincs puffer */ if ((fp->base = (char *) malloc(bufsize)) == NULL) return EOF; /* nincs hely a puffer számára */ fp->ptr = fp->base; fp->cnt = read(fp->fd, fp->ptr, bufsize); if (--fp->cnt < 0) { if (fp->cnt == -1) fp->flag |= _EOF; else fp->flag |= _ERR; fp->cnt = 0; return EOF; } return (unsigned char) *fp->ptr++; }Most már csak az a kérdés, hogy hogyan indul az egész folyamat? Az stdin, stdout és stderr számára definiálni és inicializálni kell az _iob tömböt:
FILE _iob[OPEN_MAX] = { /* stdin, stdout, stderr: */ { 0, (char *) 0, (char *) 0, _READ, 0 }, { 0, (char *) 0, (char *) 0, _WRITE, 1 }, { 0, (char *) 0, (char *) 0, WRITE | UNBUF, 2 } };A struktúra _flag részének inicializálása mutatja, hogy stdin olvasható, stdout írható és stderr írható, puffereletlen hozzáférésű.
8.2. gyakorlat. Írjuk át az fopen és _fillbuf függvényeket úgy, hogy az explicit bitműveletek helyett bitmezőket használunk! Hasonlítsuk össze a két változat forrásprogramjának méretét és a futási időket!
8.3. gyakorlat. Tervezzük meg és írjuk meg a _flushbuf, _fflush és fclose függvényeket!
8.4. gyakorlat. A standard könyvtár
int fseek(FILE *fp, long offset, int bazis)függvénye megegyezik az lseek függvénnyel, kivéve, hogy az fp állománymutatót használja az állományleíró helyett és hogy a visszatérési értéke az int típusú állapotjelzés, nem pedig egy pozíció. Írjuk meg az fseek függvényt! Gondoskodjunk arról, hogy az általunk írt fseek pufferkezelése összhangban legyen a könyvtár többi függvényével!
8.6. Példa: katalógusok kiíratása
Néha az állománykezelő rendszerrel az eddigiektől eltérő párbeszédet kell folytatnunk, pl. ha magának az állománynak a jellemzőire vagyunk kíváncsiak és nem pedig a tartalmára. Erre jó példa a katalóguslistázó program, ami feladatát tekintve megfelel a UNIX ls parancsának. A program kiírja a katalógusban lévő állományok nevét és opcionálisan még több más információt (méret, hozzáférési kód stb.) is. A parancs analóg az MS-DOS dir parancsával.
Mivel a UNIX katalógusa maga is egy állomány, az ls parancsnak csak be kell olvasni ezt az állományt és kikeresni belőle az állományok neveit, ill. ha szükséges, akkor egy rendszerhívással már meghatározható az állomány többi jellemzője is, mint pl. a mérete. Más operációs rendszerek (pl. MS-DOS) esetén az állományok nevéhez való hozzáférés is egy rendszerhívást igényel. Mi a programunkkal viszonylag rendszertől függetlenül akarunk az információkhoz hozzáférni, bár maga a megvalósítás nagymértékben függ a rendszertől.
Az elmondottakat az fsize program megírásával fogjuk illusztrálni. Az fsize program az ls parancs egy speciális változata, amely kiírja a parancssor-argumentumok listájában megadott állománynevekhez tartozó méretet. Ha az állományok egyike egy (al-)katalógus, akkor az fsize programot rekurzívan alkalmazzuk a katalógusra. Ha a programnak nincs argumentuma, akkor az aktuális katalógust dolgozza fel.
A feladat megoldását kezdjük a UNIX állománykezelő rendszerének leírásával! A katalógus egy állomány, amely az állományok neveinek listáját és az állományok helyére utaló információkat tartalmazza. A „hely” valójában egy másik táblázatba, az ún. inode táblázatba mutató index. Az inode táblázat adott állományhoz tartozó bejegyzése az állomány nevén kívül annak összes többi jellemzőjét tartalmazza. Egy katalógusbejegyzés csak két adatból, az állomány nevéből és egy inode számból áll.
Sajnos, egy katalógus konkrét formátuma és pontos tartalma az operációs rendszer egyes változatainál más és más, ezért a feladatot két részre bontjuk, amivel megpróbáljuk leválasztani a nem hordozható (rendszertől függő) elemeket. A program külső szintjén definiálunk egy struktúrát, amit Dirent-nek nevezünk és az opendir, readdir, ill. closedir eljárásokkal rendszertől függő módon férünk hozzá a katalógusbejegyzésben lévő névhez és inode számhoz. Ezeket az eljárásokat és a Dirent struktúrát használjuk szoftver-interfészként az fsize megírásánál. A rendszertől független részek megírása után megmutatjuk, hogy a rendszertől függő részek hogyan valósíthatók meg az UNIX Version 7 és System V változatánál használt katalógussal. A további változatokhoz tartozó megoldásokat meghagyjuk gyakorlatnak.
A Dirent struktúra az állomány nevét és inode számát tartalmazza. Az állománynév max. hosszát a rendszertől függő NAME_MAX érték határozza meg. Az opendir függvény egy DIR nevű struktúrát címző mutatóval tér vissza, amelyet a readdir és closedir függvények használnak. (A DIR struktúra analóg a FILE struktúrával.) Ezek a definíciók és adatok a dirent.h headerben vannak összegyűjtve.
#define NAME_MAX 14 /* a leghosszabb állománynév-komponens, az érték a rendszertől függ */ typedef struct { /* a hordozható katalógusbejegyzés */ long ino; /* inode szám */ char name [NAME_MAX+1]; /* a név és a '\0' vég jel */ } Dirent; typedef struct { /* a minimális DIR: nincs pufferelés */ int fd; /* a katalógus állományleírója */ Dirent d; /* a katalógusbejegyzés */ } DIR; DIR *opendir(char *dirname); Dirent *readdir(DIR *dfd); void closedir(DIR *dfd);A stat rendszerhívás veszi az állomány nevét, és az inode-ban található összes információt adja vissza, vagy -1 értéket, ha hibát érzékelt. A
char *nev; struct stat stbuf; int stat(char *, struct stat *); stat(nev, &stbuf);programrészlet feltölti az stbuf struktúrát a nev nevű állomány inode-jában szereplő információval. A stat függvény által visszaadott struktúra leírtása a <sys/stat.h> headerben van és tipikusan a következő módon néz ki:
struct stat /* a stat által visszaadott inode információk */ { dev_t st_dev; /* az inode eszköze (perifériája) */ ino_t st_ino; /* az inode száma */ short st_mode; /* mód-bitek */ short st_nlink; /* az állományhoz tartozó linkek száma */ short st_uid; /* a tulajdonos azonosítója */ short st_gid; /* a tulajdonosi csoport azonosítója */ dev_t st_rdev; /* speciális állományok adata */ off_t st_size; /* az állomány mérete karakterben */ time_t st_atime; /* az utolsó hozzáférés időpontja */ time_t st_mtime; /* az utolsó módosítás időpontja */ time_t st_ctime; /* az inode utolsó változtatásának időpontja */ };A felsorolt adatok többségét a megjegyzésben megmagyaráztuk. Az olyan típusok, mint a dev_t vagy az ino_t a <sys/types.h> headerben vannak definiálva, így a forrásprogramhoz azt is hozzá kell szerkeszteni egy #include utasítással.
Az st_mode bejegyzés az állományt leíró jelzőbiteket tartalmazza. A jelzőbitek definíciója szintén a <sys/stat.h> headerben található, itt csak az állomány típusát megadó jelzőkkel foglalkozunk:
#define S_IFMT 0160000 /* az állomány típusa */ #define S_IFDIR 0040000 /* katalógus */ #define S_IFCHR 0020000 /* speciális karakteres */ #define S_IFBLK 0060000 /* speciális blokkos */ #define S IFREG 0100000 /* szabályos */ /* ... */Ezek után már megírhatjuk az fsize programot! Ha a stat függvénytől kapott mód azt jelzi, hogy az állomány nem katalógus, akkor a mérete már a rendelkezésünkre áll és közvetlenül kiíratható. Ha az állomány egy katalógus, akkor azt állományonként fel kell dolgoznunk. Mivel egy katalógus további alkatalógusokat is tartalmazhat, a feldolgozás rekurzív lesz.
A main eljárás főleg a parancssor-argumentumokkal foglalkozik, előállítva az fsize argumentumait.
#include <stdio.h> #include <string.h> #include "syscalls.h" #include <fcntl.h> /* jelzők az olvasáshoz és íráshoz */ #include <sys/types.h> /* typedef utasítások */ #include <sys/stat.h> /* stat-ból visszaadott struktúra */ #include "dirent.h" void fsize(char *); /* az állományok méretének kiírása */ main(int argc, char **argv) { if (argc == 1) /* alapfeltételezés szerint az az aktuális katalógus */ fsize("."); else while(--argc > 0) fsize(*++argv); return 0; }Az fsize függvény kiírja az állomány méretét. Ha az állomány katalógus, akkor az fsize hívja a dirwalk függvényt, ami feldolgozza a katalógus összes állományát. Annak eldöntésére, hogy egy állomány katalógus-e vagy sem, a <sys/stat.h> headerben definiált S_IFMT és S_IFDIR jelzőbitek használhatók. A megfelelő programrészben ügyeljünk a zárójelezésre, mert az & precedenciája alacsonyabb, mint az == precedenciája.
int stat(char *, struct stat *); void dirwalk(char *, void (*fcn) (char *)); /* fsize: kiírja a nev nevű állomány méretét */ void fsize(char *nev) { struct stat stbuf; if (stat(nev, sstbuf) == -1) { fprintf(stderr, "fsize: nem hozzáférhető %s\n", nev) return; } if ((stbuf.st_mode & S_IFMT) == S_IFDIR) dirwalk(nev, fsize); printf("%81d %s\n", stbuf.st size, nev); }A dirwalk függvény egy olyan általános eljárás, ami az argumentumában megadott függvényt használja fel egy adott katalógusban lévő állományokra. A dirwalk megnyitja a katalógust, ciklusban végigmegy az összes állományon, mindegyikre meghívja az átadott függvényt, majd lezárja a katalógust és visszatér. Mivel az fsize is hívja az egyes katalógusok esetén a dirwalk függvényt, a két függvény rekurzívan hívja egymást.
#define MAX_PATH 1024 /* dirwalk: fcn-t alkalmazza a dir katalógus összes állományára*/ void dirwalk(char *dir, void (*fcn) (char *)) { char nev[MAX_PATH]; Dirent *dp; DIR *dfd; if ((dfd = opendir(dir)) == NULL) { fprintf(stderr, "dirwalk: nem nyitható meg %s\n", dir); return; } while((dp = readdir(dfd)) != NULL) { if(strcmp(dp->nev, ".") == 0 || strcmp(dp->, "..") == 0) continue; /* átugorja önmagát és a szülőt */ if (strlen(dir) + strlen(dp->nev) + 2 > sizeof(nev)) fprintf(stderr, "dirwalk: a név %s/%s túl hosszú\n", dir, dp->nev); else { sprintf(nev, "%s/%s", dir, dp->nev); (*fcn) (nev); } } closedir(dfd); }A readdir függvény a hívása után a következő állományt leíró információk mutatójával tér vissza, vagy NULL értékű mutatóval, ha nincs több állomány. Mindegyik katalógus tartalmaz bejegyzést saját magáról (ennek a neve "."), valamint a szülőjéről (ennek a neve "..") és ezeket a programnak át kell lépni, különben rendkívüli mértékben megnőne a futási idő.
Az eddigi programok függetlenek voltak a katalógusok fizikai szerkezetétől. A következőkben bemutatjuk a rendszerfüggő opendir, readdir és closedir függvények egyszerűsített változatát. Ezek a programok a UNIX rendszer Version 7 vagy System V változatához használhatók és a katalógusokra vonatkozó információkat a <sys/dir.h> headerből veszik. A katalógusokat leíró információk fontosabb része:
#ifndef DIRSIZ #define DIRSIZ 14 /* az állománynév hossza */ #endif struct direct /* katalógusbejegyzés*/ { ino_t d_ino; /* inode szám */ char d_name[DIRSIZ]; /* hosszú állománynév, */ /* '\0' végjel nélkül */ };Az operációs rendszer néhány változata hosszabb állományneveket is megenged és sokkal bonyolultabb szerkezetű katalógust használ.
Az ino_t típus typedef utasítással lett definiálva és az inode táblázat indexét írja le. Ez az operációs rendszer tulajdonságai alapján unsigned short típusú adat lehet, ami szabályosan használható is, de nem célszerű a programban rögzíteni, mert más operációs rendszer esetén más lehet. Így jobb megoldásnak tűnik a typedef utasítással beállított típus. A rendszertől függő adattípusok teljes halmaza a <sys/types.h> headerben található.
Az opendir függvény megnyitja a katalógusállományt, ellenőrzi, hogy annak tartalma tényleg katalógus-e (ezt az fstat rendszerhívással teszi, ami lényegében megegyezik a stat rendszerhívással, kivéve, hogy az állományleírót használja az állomány azonosítására), lefoglalja a tárban a katalógus adatait tároló struktúra helyét, majd beleolvassa az információt. Az opendir függvény:
int fstat(int fd, struct stat *); /* opendir: megnyitja a katalógust a readdir hívása előtt */ DIR *opendir(char *dirname) { int fd; struct stat stbuf; DIR *dp; if ((fd = open(dirname, 0_RDONLY, 0)) == -1 || fstat{fd, &stbuf) == -1 || (stbuf.st_mode & S_IFMT) != S_IFDIR || (dp = (DIR *) malloc (sizeof (DIR))) == NULL) return NULL; dp->fd = fd; return dp; }A closedir függvény lezárja a katalógusállományt és felszabadítja a tárban lefoglalt helyet.
/* closedir: lezárja az opendir-rel megnyitott katalógust */ void closedir(DIR *dp) { if (dp) { close(dp->fd); free(dp); } }A readdir függvény az egyes katalógusbejegyzések beolvasására a read függvényt használja. Ha egy katalógusbejegyzés aktuálisan nem használt (pl. mert az állományt töröltük), akkor az inode száma nulla és a readdir az ilyen bejegyzést átlépi. Máskülönben az inode számot és az állomány nevét elhelyezi egy static tárolási osztályú struktúrában, majd visszatér a sturktúra mutatójával. Minden readdir hívás felülírja az előző olvasáskor kapott információt.
#include <sys/dir.h> /* az adott rendszer katalógusának szerkezete itt van leírva */ /* readdir: sorban beolvassa a katalógusbejegyzéseket */ Dirent *readdir (DIR *dp) { struct direct dirbuf; /* a konkrét katalógusszerkezet */ static Dirent d; /* visszatérés: hordozható szerkezet */ while(read(dp->fd, (char *)&dirbuf, sizeof(dirbuf)) == sizeof (dirbuf)) { if(dirbuf.d_ino == 0) /* a bejegyzés helye */ continue; /* nem használt */ d.ino = dirbuf.d_ino; strncpy(d.name, dirbuf.d_name, DIRSIZ); d.name [DIRSIZ] = '\0'; /* lezárja a */ return &d; /* karaktersorozatot */ } return NULL; }Bár az fsize program meglehetősen speciális, mégis számos fontos dolgot jól szemléltet. Az első fontos megjegyzés, hogy az fsize nem „rendszerprogram”, csak olyan információt használ, amelynek formáját és tartalmát az operációs rendszer határozza meg. A második lényeges dolog, hogy ilyen programok esetén az információ rendszerfüggő leírása csak a standard headerben jelenjen meg és a program ezeket a header állományokat építse be, ahelyett, hogy saját maga deklarálná a géptől és rendszertől függő adatokat. További fontos programozási szempont, hogy a rendszerfüggő részekhez a lehető legnagyobb gonddal kell megtervezni az interfészeket, hogy a program többi része viszonylag rendszertől független lehessen. Erre a legjobb példát a standard könyvtár függvényeinél láthatunk.
8.5. gyakorlat. Módosítsuk az fsize programot úgy, hogy más, az inode táblázatban szereplő információt is kiírjon!
8.7. Példa: tárterület-lefoglaló program
Az 5. fejezetben bemutattunk egy korlátozott módon használható, veremorientált tárterület-foglaló programot. A most megírt változat nem tartalmaz korlátozásokat, a malloc és a free hívásai tetszőleges sorrendben történhetnek és a malloc szükség esetén az operációs rendszertől további tárterületet igényelhet. A tárterület-foglaló program itt megírt eljárásai jól példázzák, hogy hogyan lehet géptől függő programot viszonylag gépfüggetlen módon megírni. A programban megmutatjuk a struktúrák, unionok és a typedef utasítás gyakorlati alkalmazását is.A malloc program szükség esetén az operációs rendszertől igényel tárterületet, szemben az 5. fejezetben leírt programmal, amely a fordításkor rögzített méretű tömb elemeivel gazdálkodott. Mivel a program más tevékenységei a malloc hívása nélkül is igényelhetnek tárterületet, ezért a malloc eljárással kezelt tárterület nem összefüggő. Emiatt a szabad tárolóhelyeket a szabad blokkok listájaként tartjuk nyilván. Minden blokk tartalmazza a méretét, a következő blokk mutatóját, valamint magát a tárterületet. A listában a blokkok növekvő tárcímek szerint rendezettek és az utolsó (legnagyobb című) blokk a legelső blokkra mutat. A viszonyokat jól szemlélteti a következő ábra.
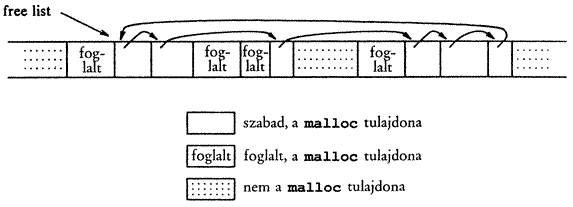
Ha igény érkezik, akkor a program végignézi a szabad blokkok listáját és az első elegendően nagy blokkot adja vissza. Ezt az algoritmust a „legelső illeszkedés” algoritmusnak nevezzük, szemben a „legjobb illeszkedés” algoritmussal, amely az igényt még kielégítő legkisebb blokkot adja vissza. Ha a blokk mérete pontosan megegyezik az igényelt mérettel, akkor kiemeljük a szabad blokkok listájából és átadjuk a felhasználónak. Ha a talált szabad blokk túl nagy, akkor a program leválasztja belőle a kívánt részt és átadja a felhasználónak, a maradékot pedig meghagyja a szabad blokkok listájában (természetesen módosítva a jellemzőit). Ha a listában nincs elegendően nagy blokk, akkor a program az operációs rendszertől egy nagyobb tárterületet kér és hozzácsatolja a szabad blokkok listájához.
A tárterület felszabadításakor szintén végig kell nézni a szabad blokkok listáját és megkeresni azt a helyet, ahová (a címe alapján) a felszabadult blokk beilleszthető. Ha a felszabadult blokk egyik oldalával illeszkedik egy szabad blokkhoz, akkor a program ezeket egybeolvasztja egyetlen nagyobb blokká, így a tárterület nem forgácsolódik szét kis részekre. A szomszédos helyzet meghatározása a címek szerinti rendezettség miatt egyszerű.
Az egyik fő probléma, amivel már az 5. fejezetben is foglalkoztunk, hogy a malloc által visszaadott tárterületnek meghatározott illesztési feltételeket kell kielégíteni ahhoz, hogy az objektumainkat ezen a területen tárolni tudjuk. Bár a számítógépek társzervezése nagymértékben különbözhet, minden gép esetén létezik egy olyan alapvető adattípus, amely ha tárolható az adott címen, akkor minden más adattípus is tárolható ott. Néhány számítógép esetén ez az alapvető adattípus a double, más gépeknél viszont az int vagy a long.
Egy szabad blokk tartalmazza a láncban utána következő blokk mutatóját, valamint a blokk méretét és ezután következik maga a szabad tárterület. A blokk elején lévő vezérlő információt fejnek nevezzük. A tárillesztés egyszerűsítése érdekében minden blokk mérete a fej méretének egész számú többszöröse és a fej pedig megfelelően illeszkedik. Ezt az adatszerkezetet egy unionnal érhetjük el, amely tartalmazza a fej struktúráját és kielégíti az illesztés szempontjából alapvető adattípusra vonatkozó igényeket. Ezt az alapvető adattípust a program long-nak tekinti. Az így kialakított adatszerkezet:
typedef long Align; /* illesztés long határhoz */ union header { /* a blokk feje */ struct { union header *ptr; /* a következő blokk címe */ unsigned size; /* a blokk mérete */ } s; Align x; /* a blokk kényszerített illesztése */ } typedef union header Header;Az Align mezőt soha nem használjuk, csak azzal kényszerítjük a fejet az illesztési feltételek kielégítésére.
A malloc a karakterben igényelt méretet felkerekíti a fejméret egész számú többszörösére. A ténylegesen kiutalt blokk mérete ennél eggyel nagyobb (egy egységnyi hely kell magának a fejnek is) és ezt a méretet írja a program a fej size változójába. A malloc által visszaadott mutató a blokk szabad területének kezdetére és nem a fejre mutat. A felhasználó a kapott tárterülettel bármit csinálhat, de ha a kiutalt területen kívülre ír, akkor valószínűleg adatvesztés és ebből adódó hiba jön létre. A blokk méretét megadó mezőre szükség van, mivel a malloc által kezelt blokkok nem összefüggő, folytonos sorozatot alkotnak, így a méretük nem számítható ki a címaritmetikával.

A base változót használjuk a folyamat indulásakor. Ha a freep (ami a szabad blokkok listájának kezdetét kijelölő mutató) értéke NULL, ami a malloc első hívásakor biztosan igaz, akkor egy elfajult szabad lista alakult ki: ez egyetlen nulla méretű blokkot tartalmaz, amely saját magára mutat. A program minden esetben végigkeresi a szabad listát és a megfelelő méretű szabad blokk keresését a freep blokknál kezdi (ami az utoljára talált szabad blokk helye). Azzal, hogy az üres blokkok listáját nem mindig az első (legkisebb című) blokkal kezdjük végignézni, a lista hosszabb használat után is homogén marad. Ha a program egy túl nagy blokkot talál, akkor annak a végéből levágott megfelelő területtel tér vissza a felhasználóhoz. Ezzel a módszerrel a blokk eredeti fejében csak a méretet kell módosítani. A felhasználónak visszaadott mutató a blokk első szabad helyét címzi (ami közvetlenül a fej utáni első hely). A program:
static Header base; /* üres lista az induláshoz */ static Header *freep = NULL; /* az üres lista kezdete */ /* malloc: általános célú tárterület-foglaló program */ void *malloc(unsigned nbytes) { Header *p, *prevp; Header *morecore(unsigned); unsigned nunits; nunits = (nbytes+sizeof(Header)-1/sizeof(Header) + 1; if((prevp = freep) == NULL) { /* nincs még szabad lista */ base.s.ptr = freep = prevp = &base; base.s.size = 0; } for(p = prevp->s.ptr; ; prevp = p, p = p->s.ptr) { if(p->s.size >= nunits) { /* elég nagy a hely */ if(p->s.size == nunits) /*a méretek egyeznek */ prevp->s.ptr = p->s.ptr; else { /* kiadja a blokk végét */ p->s.size -= nunits; p += p->s.size; p->s.size = nunits; } freep = prevp; return (void *) (p+1); }; if(p == freep) /* körbement a listán */ if((p = morecore(nunits)) == NULL) return NULL; /* nincs több hely */ } }A morecore függvény az operációs rendszertől igényel további területet. Az, hogy ezt hogyan csinálja, az alkalmazott operációs rendszertől függ. A tárterület operációs rendszertől való kérése viszonylag „költséges” (főleg időigényes) művelet, ezért ezt nem akarjuk minden malloc híváskor megtenni és a morecore függvénnyel szükség esetén egy nagyobb, legalább NALLOC egységből álló területet kérünk. A terület méretének beállítása után a morecore függvény a free függvényt felhasználva iktatja be ezt a nagyobb területet a szabad blokkok listájába.
A UNIX sbrk(n) rendszerhívása egy n bájtos tárterületet címző mutatóval tér vissza. Ha nincs tárterület, akkor a sbrk visszatérési értéke -1 (bár jobb lett volna, ha a visszatérési érték NULL). A -1 értéket a char * kényszerített típuskonverzióval kell átalakítani, hogy az összehasonlítható legyen a függvény visszatérési értékével. A kényszerített típuskonverziók miatt a függvény viszonylag érzéketlen a különböző számítógépek mutatóábrázolásával szemben. Van még egy feltétel, amit a morecore függvénynek ki kell elégíteni: a különböző blokkok sbrk függvény által visszaadott mutatóinak összehasonlíthatóaknak kell lenni. Ez a szabvány szerint nem garantálható, mert az csak az azonos tömbhöz tartozó két mutató összehasonlíthatóságát írja elő. Így a malloc függvény itt közölt változata nem teljesen hordozható, csak olyan rendszerek esetén használható, amelyek lehetővé teszik a mutatók általános összehasonlítását. Az elmondottak alapján kialakított malloc függvény:
#define NALLOC 1024 /* a minimális terület */ /* a malloc által használt egységekben */ /* morecore: az operációs rendszertől tárterületet kér */ static Header *morecore(unsigned nu) { char *cp, *sbrk(int); Header *up; if (nu < NALLOC) nu = NALLOC; cp = sbrk(nu * sizeof(Header)); if (cp == (char *) -1) /* nincs több terület */ return NULL; up = (Header *) cp; up->s.size = nu; free((void *) (up+1)); return freep; }A tárkezelő programok közül a free maradt utoljára. A függvény végignézi a szabad blokkok listáját és a megfelelő helyre beiktatja a felszabadult blokkot. A beiktatás két üres blokk közé vagy a lista végére történhet. Bármelyik esetben, ha a felszabadult blokk szomszédos egy szabad blokkal, akkor a free a két blokkot összevonja. Itt csak arra kell ügyelni, hogy a mutató a megfelelő helyet címezze és a méret helyes legyen.
/* free: visszarak egy blokkot a szabad blokkok listájába */ void free(void *ap) { Header *bp, *p; bp = (Header *)ap - 1; /* a blokk fejére mutat */ for(p = freep; !(bp > p && bp < p->s.ptr); p = p->s.ptr) if (p >= p->s.ptr && (bp > p || bp < p->s.ptr)) break; /* a felszabadult blokk a lista elejére vagy végére kerül */ if (bp + bp->s.size == p->s.ptr) { /* a felső szomszédhoz kapcsoljuk */ bp->s.size += p->s.ptr->s.size; bp->s.ptr = p->s.ptr->s.ptr; } else bp->s.ptr = p->s.ptr; if (p + p->s.size == bp) { /* az alsó szomszédhoz kapcsoljuk */ p->s.size += bp->s.size; p->s.ptr = bp->s.ptr; } else p->s.ptr = bp; freep = p; }Bár a tárolókezelési műveletek alapvetően gépfüggőek, a programok jól mutatják, hogy a gépfüggés lekezelhető és a program viszonylag kis részére korlátozható. A typedef utasítás és az union felhasználásával a tárilleszkedési feltételek kielégíthetők (feltéve, hogy az sbrk függvény a megfelelő mutatót adja). A kényszerített típusmódosítás explicitté teszi a mutató konverzióját és még a rosszul tervezett rendszercsatlakozás okozta problémát is megoldja. A programban leírt részletek a tárkezelésre vonatkoznak, de az elvek és a megközelítés más esetben is jól használható.
8.6. gyakorlat. A standard könyvtárban található calloc(n, size) függvény n darab size méretű objektum számára lefoglalt és nulla kezdeti értékkel feltöltött tárolóterület mutatójával tér vissza. Írjuk meg a calloc függvényt úgy, hogy az hívja a malloc-ot, vagy megfelelően módosítsuk a malloc függvényt!
8.7. gyakorlat. A malloc a kért méretet ellenőrzés nélkül elfogadja és a free feltételezi, hogy a felszabadítandó blokk mérete érvényes. Javítsuk ki úgy ezeket a programokat, hogy nagyobb gondot fordítsanak a hibaellenőrzésre!
8.8. gyakorlat. A malloc és a free függvények felhasználásával írjuk meg a bfree(p, n) függvényt úgy, hogy az felszabadítsa az n karakterből álló tetszőleges p blokkot. Ezt a bfree függvényt alkalmazva a felhasználó bármikor beiktathat a szabad blokkok listájába egy statikus vagy külső tömböt.
| 7. FEJEZET | Tartalom | A. FÜGGELÉK |